LaWAM: Physical Foresight for Robots Without Future-Video Generation
Latent World Action Models for efficient dynamics-aware robot policies.
Modern robot policies are becoming increasingly capable at understanding scenes and language instructions. That helps them infer what to do. Real manipulation, however, also depends on how to do it:
Not just “fold the towel,” but where the hands should move and what state the towel should approach over the next action chunk.
World-Action Models (WAMs) offer a natural way to provide this procedural signal: condition action generation on predicted futures, so the policy can reason about how the scene may evolve under embodied interaction.
The idea is powerful, but many WAMs predict future images or videos in pixel space. For robot control, this creates two practical costs:
- Latency: video generation is often iterative, delaying each policy step;
- Model capacity: large backbones spend substantial effort reconstructing textures, backgrounds, and other appearance details that may be irrelevant to the next action.
This leads to a simple question: does a robot really need a full future video to learn how to act?
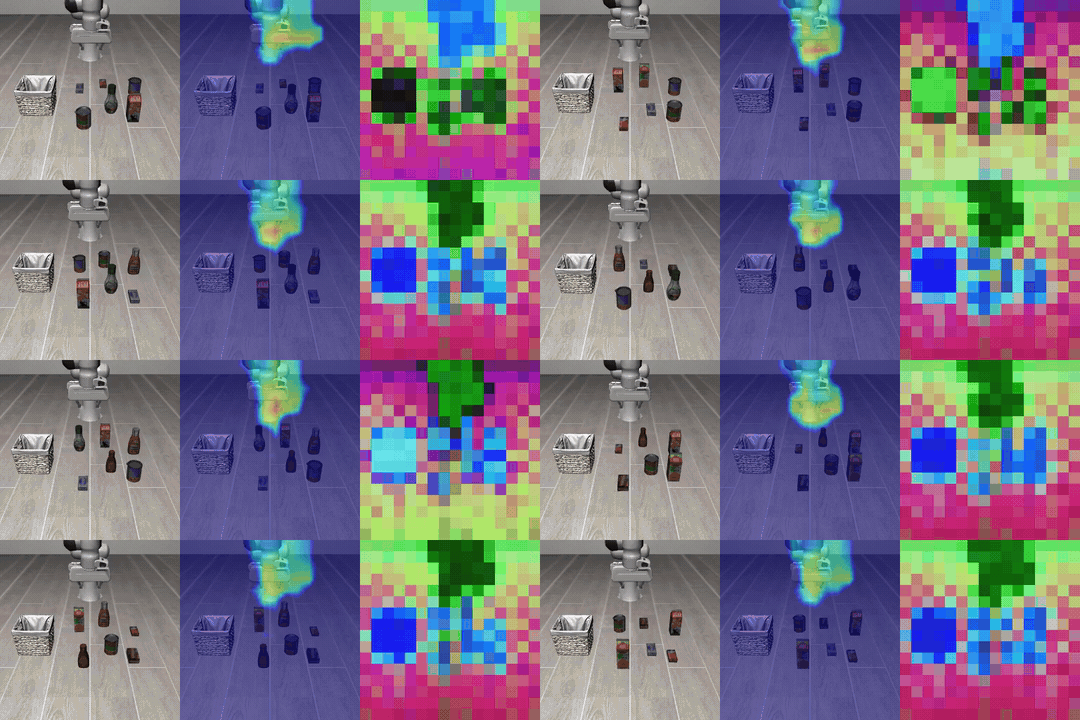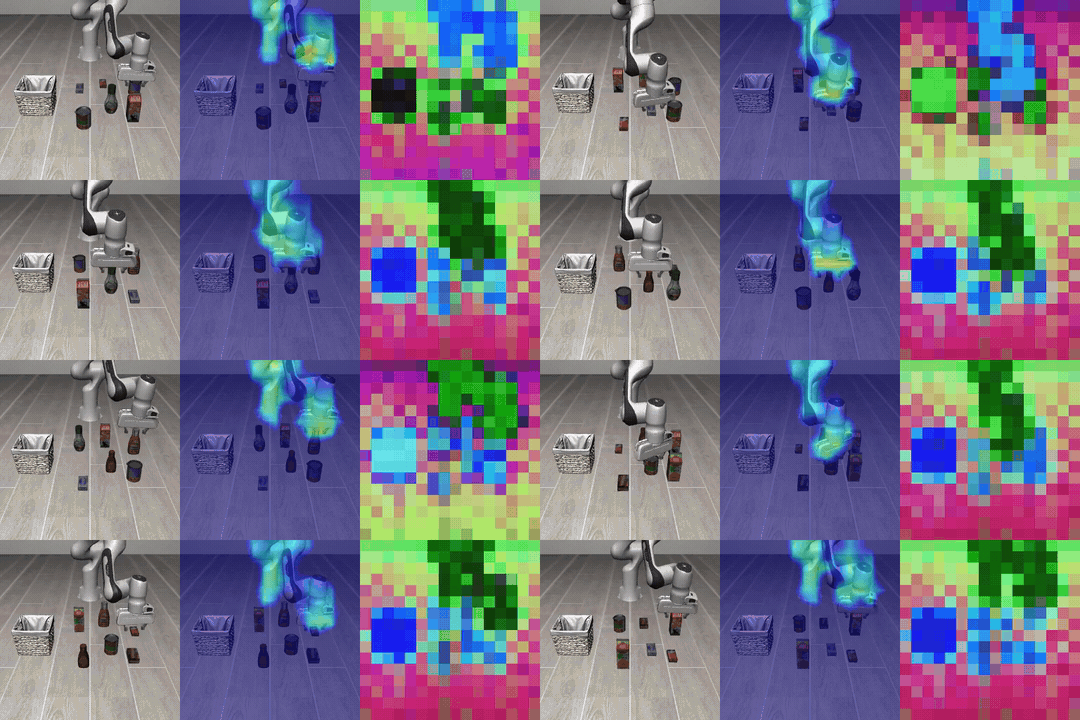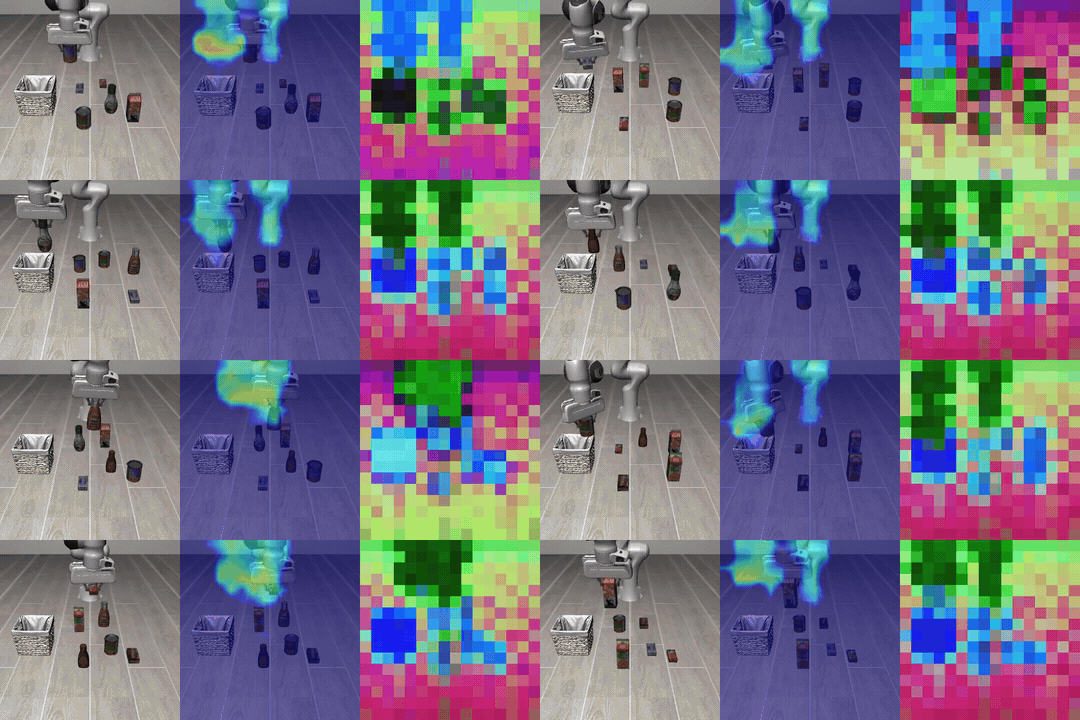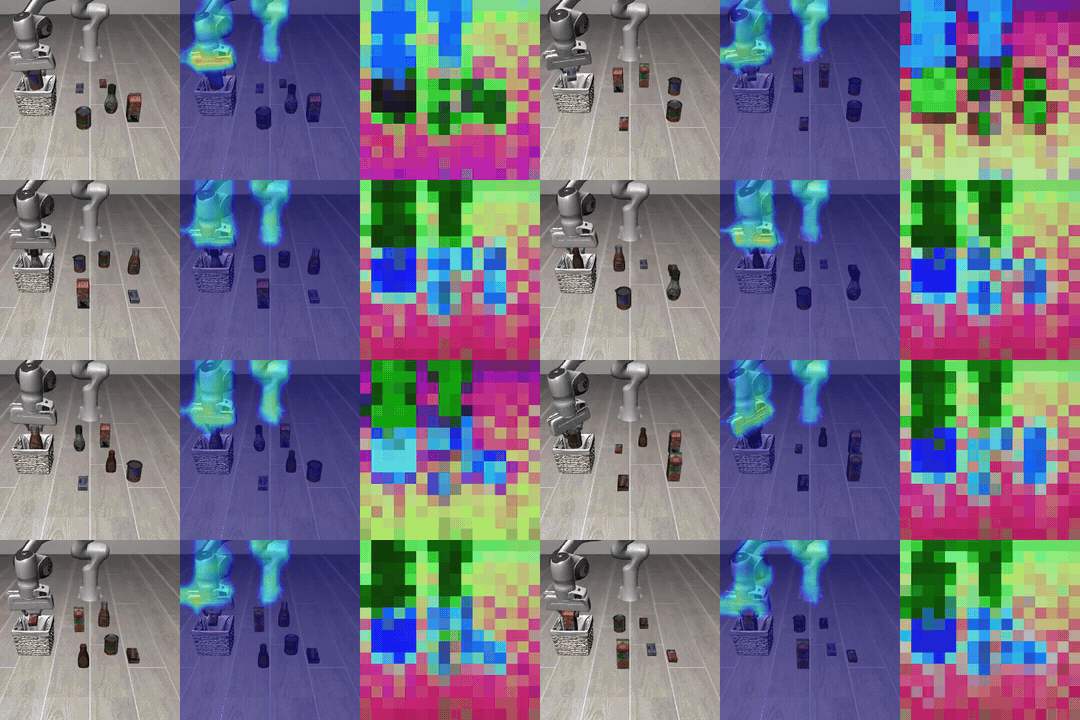
LaWAM is built around a simple premise:
Robot control does not need a visually polished future video. It needs future cues that help the policy act.
Instead of reconstructing every future pixel, LaWAM predicts the chunk-level visual future that matters for control: the scene change required by the next action chunk.
The central representation is a latent visual subgoal. It is not a future image for humans to inspect, but a policy-facing dynamics signal. It combines task intent, the current visual state, and predicted scene evolution, giving the action expert a compact target for producing the next action chunk.
We introduce LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies. LaWAM moves future prediction from pixel space into visual latent space, using compact latent visual subgoals to make robot policies dynamics-aware.
Paper and resources
Paper: LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies
arXiv: 2606.15768
Project page: rlinf.github.io/LaWAM
Code: github.com/RLinf/LaWAM
Model collection: LaWAM checkpoints on Hugging Face
LaWAM in one sentence
LaWAM addresses a central question:
How can a VLA policy use action-conditioned future prediction without paying the latency and parameter cost of pixel-space video generation?
In short:
Learn a world model in the latent space of a frozen vision foundation model, then use the predicted future latent feature as a subgoal for action generation.
Across simulation, bimanual manipulation, and real-world robot tasks, LaWAM delivers strong results:
- LIBERO: 98.6% average success rate;
- RoboTwin: 91.22% average success rate;
- Real robots: 90.0% average success rate across pick-and-place, drawer opening, and towel folding;
- Inference efficiency: 187 ms per action-chunk prediction;
- Latency advantage: up to 24x lower wall-clock latency than pixel-space WAMs;
- World-model parameters: a 230M-parameter Latent World Model, about 95% fewer world-model parameters than a 5B WAN backbone.
From generating the future to predicting a latent subgoal
A conventional pixel-space WAM typically follows this pipeline:
- Generate future images or videos from the current observation;
- Feed the predicted future back into the policy as additional context;
- Generate the robot action.
This route is intuitive, and generated futures are easy to visualize. But for control, a full future video is often more representation than the policy needs.
The robot does not need to know how every pixel will change. It needs to know:
- where the target region is;
- where the arm should move;
- what state the next action chunk should push the scene toward;
- whether the current motion is making progress toward the task goal.
LaWAM therefore uses a latent visual subgoal:
- no future-pixel reconstruction;
- no iterative future-frame generation;
- direct prediction of action-relevant future features;
- a latent future that conditions action generation.
This turns the world model from a video generator into a policy-ready dynamics interface.
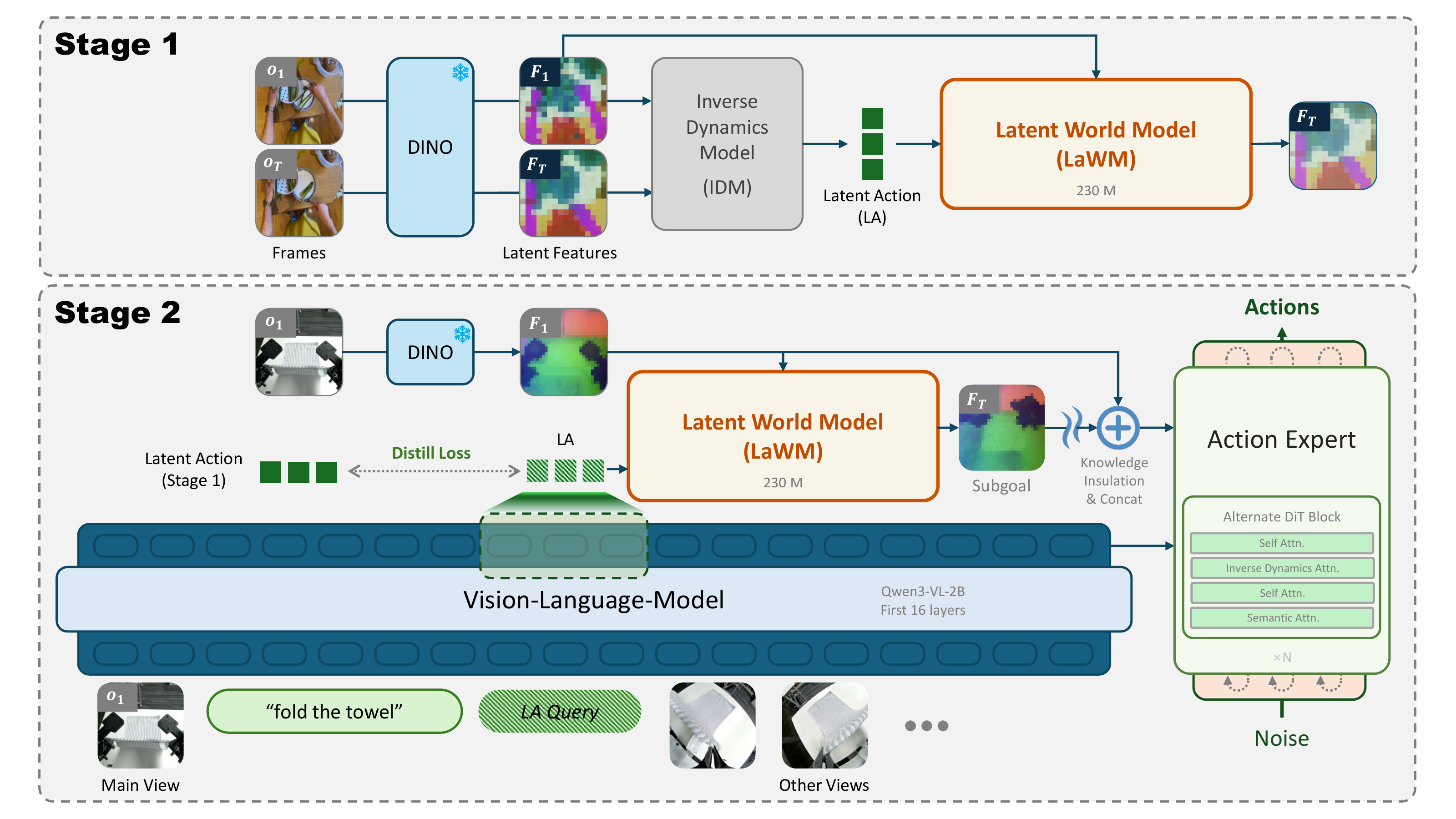
Figure: The two-stage LaWAM framework. Stage 1 learns a Latent World Model. Stage 2 injects the LaWM-predicted latent visual subgoal into the VLA action expert.
Core idea: turning the LAM decoder into a Latent World Model
The key module in LaWAM is the Latent World Model (LaWM).
LaWM comes from revisiting the Latent Action Model (LAM) paradigm. A typical LAM has two components:
- inverse-dynamics encoder: infers a latent action from current and future visual states;
- forward decoder: predicts the future latent state from the current latent state and the latent action.
Many prior latent-action VLA methods focus primarily on the latent action itself, treating it as a general action interface across embodiments and robot platforms. This is appealing because latent actions can abstract a shared notion of action intent from visual transitions across different embodiments.
That generality comes with a cost:
The more embodiment-agnostic a latent action becomes, the more embodiment-specific structure it can lose.
Different robots have different joint structures, end effectors, control frequencies, action spaces, and dynamics constraints. A shared cross-embodiment latent action is difficult to map directly and reliably into the low-level actions of a specific robot. Put differently, latent actions can represent abstract transitions, but they are not automatically the same thing as “what this robot should execute next.” Using them as direct proxies for embodiment-specific actions can therefore hurt action prediction accuracy.
LaWAM makes a different choice:
The latent action is not the final action interface. It is a bridge between the reasoning expert and the world model.
Concretely, LaWAM keeps the LAM decoder and repurposes it as a true latent-action-conditioned world model. Given the current visual feature and the policy-predicted latent action, LaWM expands the abstract transition into a task-conditioned future visual feature: the latent visual subgoal.
That subgoal is then passed to the action expert, enabling dynamics-aware action generation. LaWAM does not translate latent actions directly into real actions. It first grounds the latent action into a future subgoal for the current scene, then lets the action expert produce embodiment-specific action chunks.
Two-stage training: learn dynamics, then inject them into the policy
Stage 1: Learning the Latent World Model
The first stage trains LaWM on visual transition data. Given a current observation and a horizon observation, the model encodes both with a frozen visual encoder, infers the latent action with an inverse-dynamics encoder, and uses the decoder to predict the future latent feature.
The objective is straightforward:
Given the current latent state and a latent action, predict the future latent state.
In the paper, LaWM is pretrained on roughly 3,000 hours of robot videos and 1,500 hours of egocentric human videos. The egocentric videos are not directly used for policy integration; they help LaWM learn broader dynamics priors.
Stage 2: Training the Latent World Action Model
The second stage connects LaWM to a VLA policy. At deployment time, the future observation is unavailable, so the policy first predicts a latent action from the current observation and language instruction. LaWM then decodes it into a latent visual subgoal.
The action expert generates an action chunk conditioned on both the current semantic context and the latent future subgoal.
This stage combines:
- latent-action distillation;
- subgoal supervision;
- Knowledge Insulation, which prevents gradients from the action expert from damaging the dynamics already learned by LaWM;
- physical-time encoding, which aligns data collected at different control frequencies.
The result is more than an extra “future token.” LaWAM builds a complete interface from dynamics prediction to action generation.
Why it is fast: one latent prediction instead of iterative video generation
LaWAM’s efficiency comes from a key design:
Each action chunk requires only one latent subgoal prediction.
Pixel-space WAMs often depend on large video-generation backbones. LaWAM instead uses a 230M-parameter Latent World Model (LaWM) to predict future latent features. Compared with a 5B-parameter WAN backbone, this reduces world-model parameters by about 95%.
On LIBERO, LaWAM has a 2.3B model size and runs at 187 ms per action-chunk prediction. Under the same evaluation setup, representative pixel-space WAMs require:
- Cosmos-Policy: 1413 ms;
- Motus: 3231 ms;
- LingBot-VA: 4482 ms;
- LaWAM: 187 ms.
LaWAM preserves the future-conditioned benefits of a world model while avoiding the cost of pixel-space video generation.
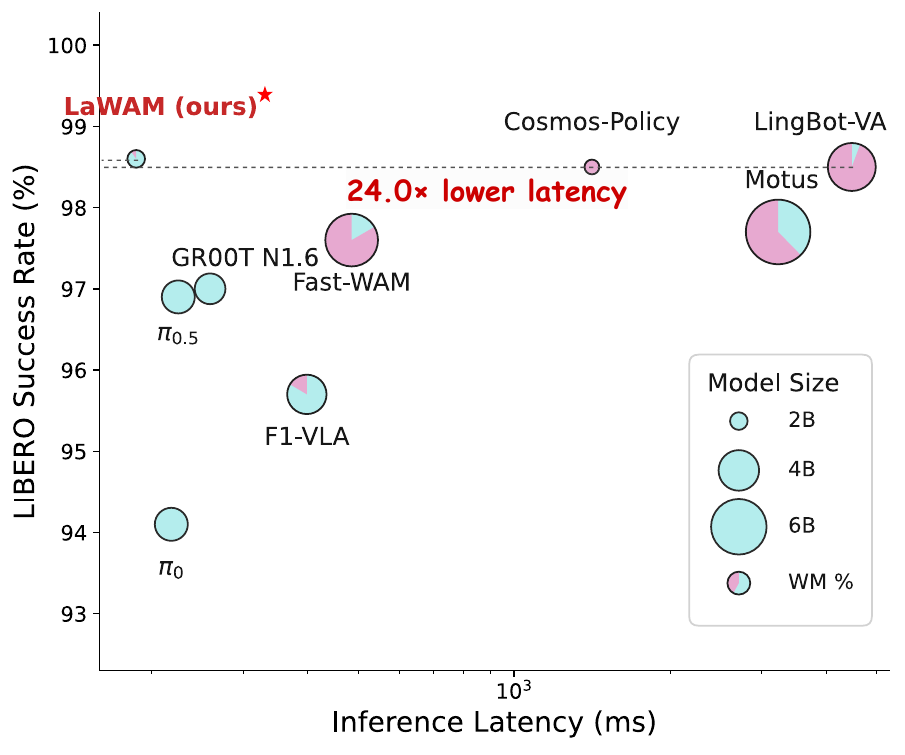
Figure: Latency-success trade-off on LIBERO. LaWAM maintains high success while significantly reducing action-chunk inference latency.
Highlight 1: high success and low latency on LIBERO
On the LIBERO benchmark, LaWAM achieves 98.6% average success rate across the four standard suites, outperforming or matching strong VLA, latent-action, and WAM baselines.
Just as important, LaWAM improves the trade-off between success and latency.
Pixel-space WAMs can gain future-prediction ability from powerful video models, but they pay with higher latency and larger world-model modules. LaWAM compresses future prediction into a latent subgoal, giving the policy useful future context while allowing the robot to act faster.
This matters especially for real robots. Robot control is not offline generation; the environment keeps changing while the model waits. Higher latency means the policy is more likely to act on stale visual information.
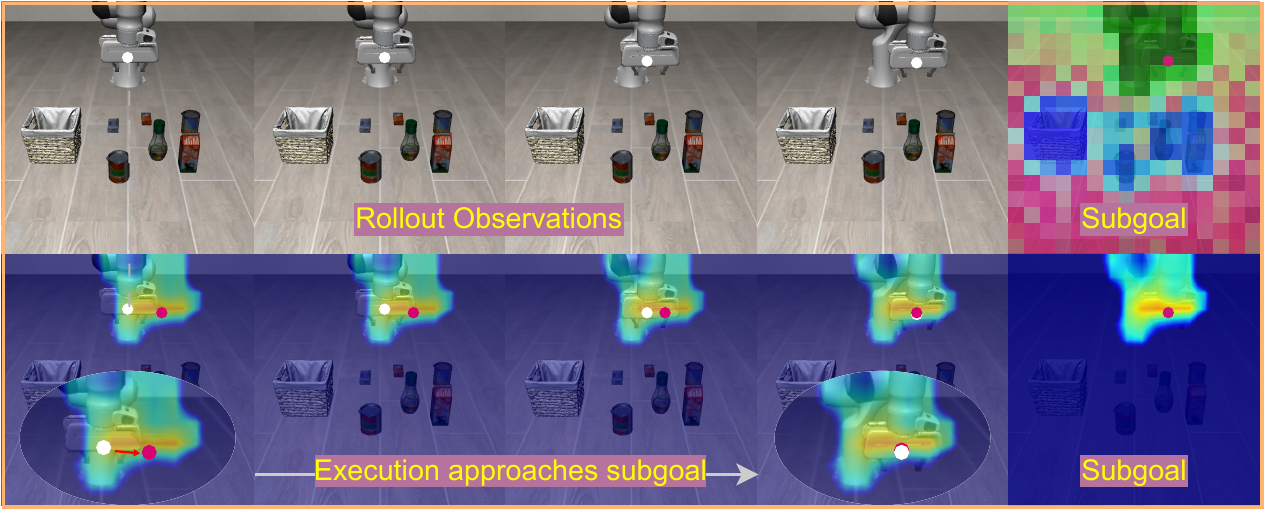
Figure: Chunk-level visualization on LIBERO. The predicted latent subgoal appears as a heatmap over the region the action will approach, and the executed trajectory moves toward the corresponding subgoal.
Highlight 2: scaling to complex bimanual manipulation on RoboTwin
RoboTwin 2.0 covers 50 bimanual manipulation tasks, making it a strong testbed for coordinated two-arm control.
LaWAM achieves:
- Clean setting: 92.64%;
- Randomized setting: 89.80%;
- Average: 91.22%.
These results show that latent subgoal prediction is not limited to short-horizon single-arm tasks. It also transfers to more complex bimanual manipulation.
LaWAM reaches the best average performance in clean scenes and remains highly competitive in randomized scenes, suggesting that the latent future interface provides useful dynamics context even under scene perturbations.
Highlight 3: real-world transfer across tasks and platforms

Figure: Representative real-world rollouts of LaWAM across pick-and-place, drawer opening, and towel folding.
LaWAM is further evaluated on three real-world tasks:
- Pick-and-place: rigid-object grasping and placement;
- Drawer opening: articulated object interaction;
- Towel folding: long-horizon bimanual deformable-object manipulation.
The evaluation covers two physical robot platforms:
- Franka Emika Panda for pick-and-place and drawer opening;
- Quanta X1 bimanual robot for towel folding.
Real-world results:
| Task | LaWAM Success Rate |
|---|---|
| Pick-and-place | 93.3% |
| Drawer opening | 86.7% |
| Towel folding | 90.0% |
| Average | 90.0% |
LaWAM achieves the best success rate across all three tasks. Towel folding is especially latency-sensitive because the robot must respond continuously to cloth motion. A high-latency policy can act on stale observations; LaWAM’s low-latency latent prediction is particularly valuable in this setting.
This comparison makes the advantage visible. When a baseline depends on pixel-level future video, the system first spends time generating a visual future, then uses it for action decisions. LaWAM skips the full future video and predicts action-relevant future features directly in latent space. In towel folding, saving this generation time lets the policy respond more promptly to the current cloth state.
LaWAM’s advantage is therefore not just that it predicts the future. It predicts the future in a form better suited to robot control: not a video for humans to watch, but a subgoal for policies to use.
Visualizing real-robot inference
The animation shows RGB execution, subgoal heatmaps, and latent PCA views. LaWAM does not generate a pixel-level future video; it encodes future dynamics as latent visual subgoals that the action expert can use.
Interpretable latent dynamics: one latent action, different scenes
The paper also asks whether LaWM truly captures dynamics, rather than merely adding an auxiliary feature.
Open-loop rollout visualizations reveal an interesting behavior: applying the same latent action trajectory to different initial observations, environments, and even embodiments produces coherent but context-specific latent changes.
As shown below, LaWM can roll out across embodiments. The same latent action can be applied not only to the source robot, but also to different robots, viewpoints, and scenes. In particular, the scenes in (d) and (e) come from previously unseen pi.website screenshots, yet LaWM still produces structured latent rollouts.
This suggests two points.
First, a LaWM trained in latent space can generalize across scenes and embodiments. It does not simply memorize a robot or background; it grounds abstract transitions back into the current visual state.
Second, it highlights the embodiment-agnostic nature of latent actions. A latent action is closer to an abstract cross-embodiment action intent than to a control signal directly aligned with low-level actions. Treating latent actions as direct replacements for real actions therefore runs into mapping difficulties caused by embodiment-specific structure.
This is where LaWAM differs from methods that only use latent action tokens. The latent action alone is not enough. The key is that LaWM expands it into a spatially structured latent visual subgoal. In LaWAM, the latent action connects the reasoning expert and the world model; the dynamics-aware policy behavior comes from the task-conditioned latent subgoal produced by LaWM.

Figure: The same latent action trajectory generates context-specific latent rollouts across different embodiments and scenes. The unseen scenes in (d) and (e) come from pi.website, showing LaWM’s cross-scene generalization and the embodiment-agnostic nature of latent actions.
Ablation: LaWM is the core source of performance
The paper conducts component ablations on LIBERO. Performance drops as parts of the latent future interface are removed or weakened.
Removing LaWM causes the largest degradation, especially on LIBERO-Long. This shows that explicit latent subgoal conditioning is a key source of LaWAM’s gains.
Removing latent-action distillation also significantly affects performance, indicating that the policy needs direct supervision from the LAM posterior to drive LaWM stably.
Together, these results show that LaWAM’s improvement does not come from a single trick. It comes from a full interface:
latent action -> latent world model -> latent subgoal -> action expert
Broader perspective
LaWAM is not just a new model. It also points to a broader view of robot world models:
Future prediction does not have to happen in pixel space.
For robot control, a future representation should be:
- Dynamic: able to express action-induced scene changes;
- Compact: not waste capacity on irrelevant pixel reconstruction;
- Usable: able to directly condition the action expert and affect action generation.
LaWAM’s latent visual subgoal sits at this intersection. It is not a future video for humans to watch; it is a future cue for policies to use.
Open resources
LaWAM resources are available here:
We hope LaWAM provides a clear, reproducible, and extensible starting point for efficient world models, VLA policies, latent dynamics modeling, and real-world robot transfer.
Closing: what kind of “imagination” do robots need?
For robots, imagining the future does not have to mean generating a full video.
What matters is whether future prediction can enter action generation at the right time and in the right form.
LaWAM’s answer is:
Compress the future from pixel space into latent space, turn the world model from a video generator into a policy interface, and give robots more efficient and more direct physical foresight.
When the world model stops reconstructing every pixel and focuses instead on action-relevant dynamics, it can more directly serve robot control.
LaWAM lets robots move toward the future without drawing it first.
We invite readers to explore the paper, project page, code, and models, and to follow our future work on latent dynamics modeling.
BibTeX
@misc{chen2026lawam,
title = {LaWAM: Latent World Action Models for Efficient Dynamics-Aware Robot Policies},
author = {Chen, Jialei and Wang, Kai and Chen, Kang and Chen, Shuaihang and Gao, Feng and Tang, Wenhao and Li, Zhiyuan and Liu, Weilin and Yao, Zhuyu and Li, Boxun and Xu, Yuanbo and Yu, Chao},
journal = {arXiv preprint arXiv:2606.15768},
year = {2026},
archiveprefix = {arXiv},
primaryclass = {cs.RO},
}